Github primer for the uninitiated
This is a post on how to get to grips with github concepts and repositories which can seem very daunting when you start out. It's a redraft of a blog post which I initially had on my employer's intranet but haven't posted it publicly until now. It was very popular and people have asked me for copies of it so here it is in the open for everyone to enjoy :-) And if you were wondering why people needed a new source control system in git, it's down to Linus Torvalds.
(NOTE: If you're visiting my post looking for my shell aliases, they're in the ALIASES section near the end of this document)
1. REPOSITORIES, PROJECTS AND PULL REQUESTS
The examples in this article will use the public nodejs repository.
When working with any codebase there are likely two repositories you will be interested in. One is the main official repository that everyone uses on github (For example http://github.com/nodejs) and the second is your own copy of that repository on the github server (For example https://github.com/sxa. Under repositories you will find projects (for example http://github.com/nodejs/node is a project). Within your own repository several of the projects will likely be "forks" (copies) of the codebase from the main official repositories to host your changes made in isolation of the main repository. For example I have a http://github.com/sxa/node fork of http://github.com/nodejs/node. While you can set your project to allow anyone who's a member to commit changes directly into the main official repository (you might work this way for your own repositories), it is more common for people to create and work on a fork and submit what's called a "pull request" back to the original repository.
Forking and pull request creation are the two operations that must be done on the web interface (there are also the tools at https://hub.github.com/ which you could use that I might talk about in a future article). Forks are created by going to the official repository's URL in your browser and clicking the <<fork>> button at the top of the screen. If you are a member of different organisations it may give you the option to create the fork in one of those namespaces, but the most common use case is to put it in your own namespace. For pull requests, use one of the magic keywords to link it to a relevant issue where applicable.
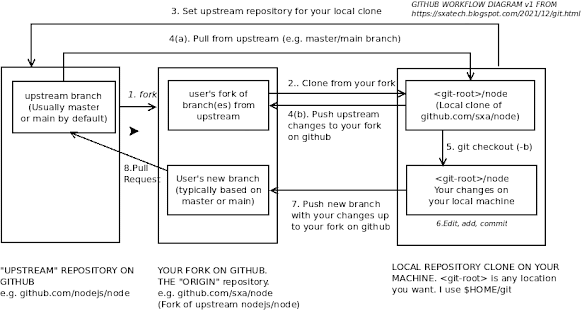
Before I start, I'm going to show this diagram based on one from an ex-colleague Geraint Jones which will serve as a useful visualisation to refer to as you read the rest of this as it shows the steps involved. While you're getting started you may wish to print the out and have it in front of you while you work as a reminder. Alternatively you may find it useful to draw out your own version piece by piece on a whiteboard as you read through this post.
2. SSH KEYS
You may have noticed that in all the above repository locations in the introductory paragraphs I used an https URL. However for your day to day work (and to access any private repositories) you'll generally be accessing git over an ssh connection to get the access to push to your repositories (it is also possible to use an access token over https, but not password authentication. Details are here so I won't cover that). For this you need to have an ssh keypair on your machine (Use ssh-keygen if you haven't already got one, on Windows run with WSL or use PuTTy) and send your id_rsa.pub file to github using the "New SSH key" button on https://github.com/settings/keys). Once you've done this you'll be able to access the repositories by converting a URL such as http://github.com/sxa/node as git@github.com:sxa/node (Note that the / after github.com is now a : in the git:// URL) Both addresses refer to the same repository, but via a different connection method.
3. LOCAL CLONES
Most git operations are done on your local machine. You clone the repository (typicaly your fork) which takes a local copy of it, and then perform your work on the clone, and "push" it back to the repository you cloned from once you've completed the changes you wish to make. By default it will checkout to a directory named the same as the project, but you can specify an alternative checkout directory when you clone:
- git clone git@github.com:sxa/node <alternative_checkout_directory> [-b branch]
- cd node <<< Or the alternative_checkout_directory if you specified one!
4. BRANCHES
Within a project you can have multiple branches. These are frequently used for different variations of the "master" branch and some projects use branches for each product release to be able to service them (others use different repositories). master is the default branch in most projects, although in the wake of the BLM movement there is a move towards using main, with other branches in upstream repositories typically used for any special features or specific alternative supported release lines, so you may find branches named after older version numbers e.g. v12.x. Within your cloned fork of a project you will generally create and work on a branch in order to create a set of changes to implement some functionality, push the branch back up to your repository on github, and then submit that branch as a pull request into the upstream project's repository to request it to be merged. You can create a new branch within your clone using the following command. Subsequently you can switch between branches that already exist by using the same command without the -b option.
- git checkout -b my_new_feature_branch
And for when you inevitably forget to do that bit and end up working on master:
We've all been that idiot, probably several times, so we all need to keep this sequence of commands in our heads :-) #github https://t.co/qCv0e4o7rk
— Stewart X Addison 🇪🇺 (@sxaTech) March 4, 2018
If you use git stash, you can recover your "stashed" changes with git stash apply which will re-apply the latest stashed change. You can also use git stash list to show the list of stashed changes and apply them by using a parameter to the command e.g. git stash apply stash@{0} (or you can throw away a stash with git drop stash@{0}. If you want to throw away your changes, you can use git checkout -- <filename>.
5. MAKING CHANGES
Now that you've done all that, we can get to doing the things you're here for. Once you've created a branch you can start making changes to it. Just start by editing the files using whatever method you prefer in your favorite editor - we won't judge you! You can then check up on what files are changed relative to the original clone with:
- git status
Changes which aren't yet "staged" will be shown in red if you have an appropriate terminal. If you are happy that everything in there is correct for submission back to your repository you can then use
- git add -A
Which will stage all of those files which were listed in red (including backup files if your editor creates them in the area, in which case you probably don't want to use -A (if you do accidentally then run git reset HEAD to undo it). You can use:
- git add -u
instead to only include the changes to existing files, not the "Untracked" ones - so new files you've created will need to be added explicitly before you commit the changes. If the list in the git status output doesn't look right or you are paranoid - which I usually am - you can stage the individual files with the following command. If they are in different directories the filenames should be listed relative to where you currently are in the tree:
- git add <file1> [file2 file3 ... fileX]
This can be used for new files, or for existing files that you have changed. you can also use
- git rm <file1> [file2 file3 ... fileX]
if you want to delete files within your branch. Once you've done all your additions and removals you can run "git status" again to check which files are being staged (the green ones if your terminal supports colours). When you're happy you've done them all and added them, you can "bundle them up" into a single commit using one of these commands:
- git commit
- git commit -m "Comment for my new set of changes"
The first of these will fire up an editor for you to edit the commit message, then second will add a one line commit directly from the command line
Every commit gets an ID associated with it so you can reference it later. The ID is a SHA hash of the commit and various bits of metadata around it. Often you'll see the commit ID truncated to just show the first 7 hex digits of it. This shortened form can generally be used anywhere you need to specify the ID on a command line.
Once you've committed the changes (remember that everything so far is still just in your local clone on your machine) you can then push the branch back to your repository. If you've forgotten the name of your branch you can run "git branch" to check (normally you shouldn't be doing things on the "master" branch!)
- git branch
- git push --set-upstream origin my_new_feature_branch
Once that's done your repository on the git server should show the new branch and have a button to create a pull request back to the repository you initially forked from. If you make subsequent changes you can generally just use git push on its own without specifying the g---set-upstream origin parameter.
Once your pull request has been merged the git UI will tell you the branch can be deleted - it will give you a button on the UI to do this on the server, but from the command line you can use:
- git branch -D my_new_feature_branch
- git push origin :my_new_feature branch (or git push origin -d my_new_feature_branch)
Note that -D in the first of these commands is a "force delete". If you use -d instead at this point it will tell you the branch has not yet been merged. This is because your upstream branch has not been updated in your local repository, only on the server copy. The next section will resolve that so you would be able to use -d instead of -D.
6. KEEPING YOUR FORK UP TO DATE
When you take a fork you get a copy of the repository you forked from as it is at this point in time. It will become out of sync with the main (upstream) repository over time (including when any pull requests you submit back to upstream gets merged back in) and you will need to keep the branches in sync to avoid ending up with conflicts when you merge your changes. This needs to be done from your local clone of your repository.
To do this you need to checkout the branch you want to re-sync with the upstream official repository (let's assume "master" as that's the most common case for these examples but as mentioned earlier "main" is becoming more typical), but it can be any branch from the main official repository that you need to resync with your fork). From your local clone of your repository issue this command:
- git checkout master
We are now going to talk about "remotes". By default when you clone you get one "remote" which points to the repository which you cloned from. You can check which remotes you have in your clone by using:
- git remote -v
By default this will show one, named "origin" pointing at whatever the URL was that you used in your initial "git clone" command. In order to resync with the upstream version, you now need to add another remote pointing at the upstream repository you want to sync with. So for example if I wanted to keep my sxa/node master branch in sync with the nodejs/node master branch here's what I'd do:
- git remote add up https://github.com/nodejs/node
Terminology clarification - in this section "upstream" (I personally use "up" to refer to this in my git remote commands) is being used to refer to the repository that you initially forked from - up until now I have been referring to it as the "main official" repository, but in this context "upstream" makes more sense.
You now need to "fetch" the branch from the upstream repository and then "merge" from it. git provides a handy way of doing both of those in one with the easier to remember "pull" command:
- git pull up master
This will show the details of all the updates from the upstream project that aren't in yours, and it will now have merged them into your local clone of the project. You should now "push" these back to the branch of your project on the git server. Since you're already sitting on the master branch (due to the "git checkout master" a few steps back) within the clone of your repository this doesn't need to be qualified any further:
- git push
(Note that in this case, git push on it's own is a short form of git push origin master since origin is an assumed default remote repository, and master is the name of local branch you're working on - the last one you issues a git checkout operation on, so is the default)
7. RECOVERING WHEN YOUR FORK BECOMES CORRUPTED
If the master branch in your fork of an upstream repository ever gets in a mess (often this will show up as unexpected extra commits showing up in a pull request, and often because at some point you edited files in master instead of a branch) then you can clean it up by forcing a full resync with the upstream master branch as follows:
- git checkout master
- git fetch up
- git reset --hard up/master
- git push -f origin master
Your fork of the master branch will now be in sync with the upstream repository. If you had any branches off the "corrupt" master branch you can checkout your branch then run git rebase master, although you may need to merge some conflicts for that to succeed.
If you have erroneous files lying around in your local filesystem (such as backup files) then this command will get rid of them all, starting from where you are in the git repository downwards (i.e. it won't affect things in parent directories even though they'll be reported in the output from git status)
- git clean -fdx
Or if that's too scary, run it with -n first
If you've made a complete mess of a file and want to get it back to the original version, then use
- git checkout -- yourfile.txt
8. FIXING UP INCORRECT COMMITS
Every so often you'll make an error in your commits (yes, let's admin we're not perfect!) If you just want to change the commit message you can use the following. Bear in mind that many projects have standards for commit messages so you may be asked to adjust them during a review cycle.
- git commit --amend -m "New commit message"
If you've made a mistake in the code you can either just add a new commit, or if you wish to replace the error then run through the normal "edit file", "git add", "git commit -m banana" (banana is just a random string that will get removed) and then run:
- git rebase -i HEAD~2
This will fire up your text editor with the last two (or more if you change the number) after HEAD~) commits and let you select what to do with each. Leave "pick" against the original one, and check "pick" to "f" against the line with "banana" (you can also use "s" for "squash" instead of "f" for "fixup" if you want to merge the second commit message into the first). Save your editor and your "banana" commit will be merged into the previous one. If you had previous run "git push" to send the original commit to the remote server then you'll need to use "git push -f" to force a new version of the amended commit. Normally the force option is a bad idea since it can result in people's local repositories getting our of sync, but if you are the only one working on a branch and you only have one clone you're generally safe to use it. The gsq alias which I will mention later can make this "squashing" process a bit quicker.
Alternatively if you just want to dispose of a commit you've already pushed back to your repository and start again, find the last good commit id and run
- git push -f origin <commit_id>:<branch_name>
Rebasing is quite a complex topic overall (what I've just described is a simple, but common, example of it) - see https://git-scm.com/book/en/v2/Git-Branching-Rebasing for the full git documentation on the subject or https://git-scm.com/docs/git-rebase for the specific documentation on the rebase command.
9. SHOWING COMMIT HISTORY AND IDS
To view the commits in your repository you can use:
- git log
This will show you the commit ID/has, the author of the commit, date and time it was made and the commit message. Although that format isn't always the best for scanning through last numbers of commits, so the log command provides you with the ability to format the output in any way you wish. Here's what I tend to use:
- git log --pretty=format:"%h %ad | %s%d [%an]" --graph --date=short
See https://git-scm.com/docs/pretty-formats for a list of things you can add to the pretty format string. The above one displays only the shorted 7-digit version of the commit hash which I referred to before.
There are various other things you can add to filter them - see https://www.git-scm.com/docs/git-log for a full list, but here are a couple of examples:
- Show only commits in the last two weeks: git log --pretty=oneline --since="2 weeks"
- Show only the latest 10 commits (Can be combined with other options, doesn't paginate): git log -10
- Show commits from a particular user (sxa in this example): git log --author="sxa"
10. MORE ADVANCED USE: CHERRY-PICK AND BISECT
You can use:
- git cherry-pick <commit_id>
to take a commit from another branch and apply it to yours. This would often be used if you have a bug fix that's in a development branch that you want ported to a supported service stream that needs the fix.
git bisect is an extremely useful tool for finding out which commit introduced a particular bug. The process for using it is as follows, assuming your currently checked out code is one that shows the problem (an "bad" level)
- git bisect start
- git bisect bad
- git bisect good <known_good_commit>
- Run whatever test you have
- Run either git bisect good or git bisect bad based on whether the test succeeded at this code level, then go back to the previous step and try again
- git bisect reset
Once you've identified the commit, if you can't immediately figure out how to fix it, you may wish to do another commit reverting the problematic one. Fortunately that's easy too!
- git revert <commit_id>
Then use git push to send it back up to your repository
11. ALIASES
If you're using git a lot on the command line (especially if you're using a git log special format as in the last example!) you may find some aliases make for quicker operations. These are the ones I use:
| ALIAS | MEANING | COMMAND (ALIAS DEFINITION) |
| ga | add files | git add |
| gaa | "add all" | git add -A (NOTE: Will also add backup files if your editor generates them in the clone area) |
| gcm | commit with message | git commit -m |
| gb | show branches | git branch |
| gbq | current branch | git rev-parse --abbrev-ref HEAD |
| gs | status | git status |
| go | goto branch | git checkout |
| gh | change history | git log --pretty=format:"%h %ad | %s%d [%an]" --graph --date=short |
| gsq | squash 2 commits | GIT_SEQUENCE_EDITOR=git_fixup_editor git rebase -i HEAD~2 #!/bin/sh |
The gsq alias and git_fixup_editor script allows you to fixup a change with:
- Edit the file
- ga filename.txt && gcm banana && gsq && git push -f
As an alternative to the above shell aliases you can also uses aliases within git, but I prefer not to do that as it might lead you to assume they're always present e.g.
- git config --global alias.gh 'log --pretty=format:"%h %ad | %s%d [%an]" --graph --date=short'
will allow you to use "git gh" to show a one-per-line log history of the repository
12. SUMMARY OF EVERYDAY COMMANDS:
These correspond to the step numbers in the diagram near the start of this blog post.
Step 1: Fork the main official (upstream) repository to your own namespace on the web interface (one time operation)
Step 2: Clone your fork of the project within the repository that you wish to work on (often a one time operation): git clone <repository_url>
Step 3: Use "git remote add up <original repository you forked from> to set an upstream repo (Needed after you do a new clone - use an https:// URL instead of a git@ URL in order to avoid accidentally pushing back to it)
Step 4: If you need to because you're out of date, sync the project with the version in the upstream repository: git checkout master; git pull up master; git push
Step 5: Create a branch for your changes using git checkout -b <branchname>
Step 6: Make changes then "git add <files>"; "git commit -m "My commit comment""
Step 7: Push your changes up to github with "git push origin <branchname>".
Step 8: Submit a pull request using the web interface to get your changes integrated into the upstream project via https://<upstream_repository>/pulls
Step 9; Once the pull request is merged you can delete the branch if you wish through the UI or with: git push origin --delete <branch_name>
Comments
Post a Comment